Architecture
The Mentat system is a platform enabling to unify the collation and subsequent processing and managing of various detected security events coming from a wide range of different detection systems. It was designed to aid CSIRT security team to process and manage huge amount of security information for the backbone network size.
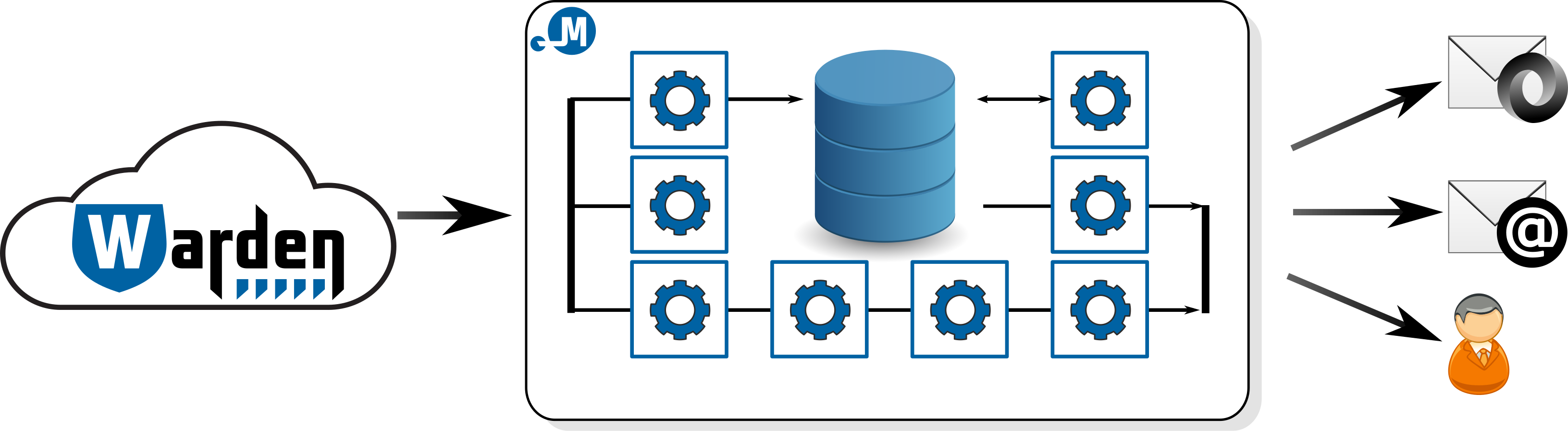
General overview of the Mentat system
Mentat is designed as a distributed modular system with the emphasis on security, extendability and scalability. The core of the system is implemented similarly to the Postfix MTA. It consists of many simple modules (or daemons), each of is responsible for performing a particular simple task. This approach enables smooth process-level parallelization, configurability and extendability.
Mentat itself does not have any network communication protocol for receiving events or messages from the outside (however nothing stops you from implementing your own module). Instead it relies on the services of Warden system, which is the security information sharing platform.
Overall system architecture
All modules use the same custom core framework called PyZenKit, which makes implementing new modules an easy task. The implementation language is strictly Python3 with no attempts whatsoever to be compatible with Python2. The system uses the PostgreSQL database as persistent data storage. The system uses the IDEA as data model, which is based on JSON. It was specifically designed to describe and contain a wide range of different security events and with further extendability in mind.
The diagram below provides an overview of the existing architecture of the Mentat system.
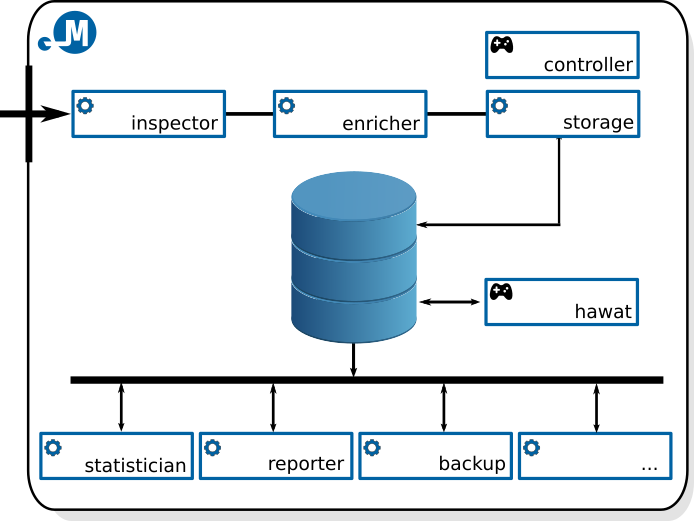
Architecture of the Mentat system
The Mentat system consists of modules allowing processing events both in real-time and retrospectively over a particular period of time. At present moment, the following most important modules for real-time processing are available:
- mentat-inspector.py
This module enables the processing of incoming IDEA messages based on the result of given filtering expression. There is a number of actions that can be performed on the message in case the filtering expression evaluates as true. The most common and useful use cases are message classification, verification, filtering and conditional processing branching. (more information)
- mentat-enricher.py
This module enables the enrichment of incoming IDEA messages with additional information, like resolving target abuse`s contact (for the reporting purposes), geolocation and ASN resolving. Implementation of further enrichment operations is planned and custom enrichment plugins are supported (hostname/ip resolving, passive DNS, …). (more information)
- mentat-storage.py
This module enables to store incoming IDEA messages in a database (PostgreSQL). (more information)
You can find full list of real-time message processing modules in appropriate documentation section.
Most modules enabling retrospective event processing are based on regularly re-launched scripts (i.e. crons). At present moment the following most important modules enabling retrospective event processing are available:
- mentat-statistician.py
This module enables statistical processing of messages over a given self-defined time period. At present, the module is preset to five-minute intervals. For each of these intervals, it determines the frequency of events according to detector type, event type, IP address etc. These statistical reports are stored in a separate database and can later support an overview of system`s operation, provide underlying data for other statistical reports or for the creation of dictionaries for a web interface. (more information)
- mentat-reporter.py
This module is responsible for periodical reporting of events via emails directly to the responsible administrators in target networks. (more information)
- mentat-informant.py
This module is responsible for periodical reporting of processing statistics via emails. (more information)
You can find full list of message post-processing modules in appropriate documentation section.
Little bit on the side is a big collection of utility and management scripts and tools that attempt to simplify repeated dull tasks for the system administrator. Some of the most useful ones are following:
- mentat-controler.py
A script enabling to control all configured deamons/modules on a given server. (more information)
- mentat-backup.py
A configurable module enabling periodical database backups. At present, a full backup of system tables (users, groups, …) is created once a day while IDEA event table is backed-up incrementally. (more information)
- mentat-cleanup.py
A configurable module enabling periodical database and filesystem cleanups. (more information)
You can find full list of utility and management modules in appropriate documentation section.
The last important component of the system is a web user interface:
- mentat-hawat.py
Customizable and easily extentable web user interface based on Flask framework. (more information)
Module architecture
As mentioned above, all system modules, including continuously running deamons or periodically launched scripts, use a simple common framework called PyZenKit, which ensures all common features:
Application life-cycle management.
Configuration loading, merging and validation.
Daemonisation.
Logging setup.
Database abstraction layer.
Abstract layer for working with IDEA messages.
Statistical data processing.
WHOIS queries, DNS resolving.
Script module architecture
Todo
Work in progress, soory for the inconvenience.
For further details please read the documentation and study source code of following libraries:
Daemon module architecture
All continuously running deamons operate as pipes, i.e. the message enters on one side, the module performs relevant operations and the message reappears on the other side. To facilitate message exchange between individual deamons, alike in Postfix MTA, the message queues are implemented by means of simple files and filesystem directories (see appropriate subsection below for more details).
Internally the daemon modules use the event driven design. There is the infinite event loop and events are being emited from different parts of the application and then are ordered into event queue. Scheduler takes care of fetching next event to be handled and is reponsible for calling appropriate chained list of registered event handlers.
To further improve code reusability each of the daemon modules is composed of one or more components, which are the actual workers in this scenario, the enveloping daemon module serves mostly as a container. There are different components for different smaller tasks like fetching new message from filesystem queue, parsing the message into object, filtering the message according to given set of rules etc. These components can be chained together to achive desired final processing result.
Following diagram describes the internal daemon module architecture with emphasis on event driven design and internal components:
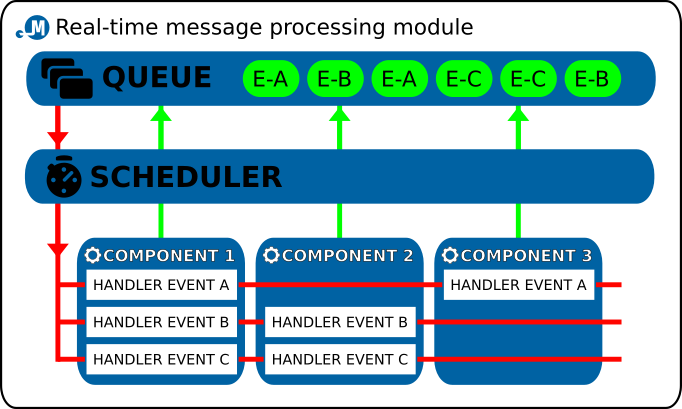
Architecture of the Mentat daemon module
So, when implementing a new deamon, one only needs to design and implement the actual processing; everything else is provided for automatically, including the selection of a message from the queue and subsequent upload into the queue of another daemon in the processing chain.
For further details please read the documentation and study source code of following libraries:
Filesystem message queue protocol
To facilitate message exchange between daemon modules a very simple filesystem-based message exchange protocol (aka. filer protocol) was designed and implemented. It is inspired again by Postfix MTA.
The protocol uses designated filesystem directory with following substructure for exchanging the messages:
incoming: input queue, only complete messages
pending: daemon work directory, messages in progress
tmp: work directory for other processes
errors: messages that caused problems during processing
Key requirement for everything to work properly is the atomic move operation on filesystem level. This requirement is satisfied on Linux system in case the source and target directories in the move operation are on the same partition. Therefore never put queue subdirectories on different partitions and be cautious when enqueuing new messages. To be safe use following procedure to put new message into the queue:
create new file in tmp subdirectory and write/save its content
filename is arbitrary, but must be unique within all subdirectories
when done writing, move/rename the file to incoming subdirectory
move operation must be atomic, so all queue subdirectories must be on same partition
Following diagram describes the process of placing the message into the queue and the process of fetching the message from the queue by the daemon module:
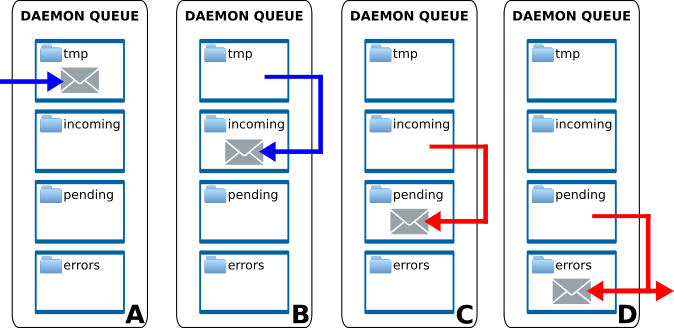
Mentat message queue protocol
Blue arrows are filesystem operations performed by the external process, that is placing new message into the queue. It is clear, that according to the procedure described above the message is first placed into the tmp and then atomically moved into incoming. Red arrows indicate filesystem operations performed by the daemon process itself. By atomically moving the message from incoming to pending it marks the message as in progress and may now begin the processing. When done, the message may be moved to the queue of another daemon module, moved to the errors in case of any problems or even deleted permanently (in case the daemon module is last in message processing chain).
The atomic move operation from incoming to pending serves also another purpose, which is locking. When multiple instances of the same daemon module work with the same queue the atomicity of the move operation makes sure that each message will be processed only once. All daemon modules are prepared for this eventuality and are not concerned when messages magically disappear from the queue.
Web interface architecture
The web interface for Mentat system is called Hawat: Web user interface and it is built on top of the great Flask microframework. However the micro in the name means, that to make things more manageable and easier a suite of custom tools had to be implemented to enable better interface component integration.
Flask already provides means for separating big applications into modules by the blueprint mechanism. This is used very extensively and almost everything in the web interface is a pluggable blueprint.